[ Ugeseddel 36 pdf,
docx
| slides
pdf,
pptx
]
[ Ugeseddel 40 pdf,
docx
| slides internetsøgemaskiner
pdf,
pptx
| slides MapReduce
pdf,
pptx
| øvelser
pdf,
docx,
pagerank.xls
pagerank2.xls
pagerank3.xls
]
Bemærk: Øvelserne bør laves i den angivne rækkefølge. Opgaverne 1-10 omhandler alle sortering, hvoraf opgave 10 er afleveringsopgaven. Løsninger til opgave 11 vil blive gennemgået til forelæsningen kl. 12.15-13.00 under tirsdagens Open Learning Center, hvorfor det er en god idé at nå at se på denne inden forelæsningen. Opgaverne 12-17 illustrerer andre algoritmiske problemstillinger. Endeligt omhandler opgaverne 18-19 matematikken der anvendes når man skal vælge blandt forskellige algoritmer. Det forventes ikke at man når alle opgaver - dog bør man som minimum nå opgaverne 1-11. I opgaverne hvor der anvendes applets, bør I anvende jeres årskortnummer som id.
| Til mange af de følgende øvelser er givet en boks som denne. Disse er ikke en del af øvelserne, men blot yderligere information for at sætte opgaverne i et historisk perspektive, give anvendelser etc. Bemærk at de refererede artikler er nogle af de mest dybe algoritmiske artikler, og derfor i sværhedsgrad er langt ud over hvad man kan forvente på første år på datalogi studiet. |
Klip de udleverede ark (card.pdf) ud langs de tynde linier. Derved fås en stak kort med tilfældige numre. Kortene kan blandes ved at rode dem rundt på bordet og samle dem i en stak bagefter - dette skal gøres før hver brug af kortene i de følgende øvelse (hvad der ikke vil blive nævnt igen).
Opgaven er nu at sortere kortene (til stigende orden, d.v.s. mindste kort øverst).
Overvej kort, hvordan I vil gøre, og afprøv så metoden (lad gerne flere prøve samtidigt).
Spørgsmål:
Beskriv metoden I brugte detaljeret nok til at andre kan udføre den (5-10 liniers svar).
| Øvelserne 1-10 beskæftiger sig med algoritmer til at sortere en mængde af elementer. Dette er et fundamentalt problem som opstår som et centralt delproblem i rigtigt mange sammenhænge. Formålet med denne øvelse og øvelse 2 er, ud over at forsøge at designe en sorterings-algoritme, at opnå den indsigt at når man formulerer en algoritme, så skal beskrivelsen være så præcis at den entydigt beskriver fremgangsmåden. |
Find en nabogruppe, og udveksel jeres beskrivelse fra øvelse 1 med hinanden. Lad to eller tre forskellige personer i jeres gruppe udføre nabogruppens metode (gerne samtidigt, så flest muligt laver noget). Tag tid for alle, og find gennemsnittet.
Spørgsmål:
Angiv gennemsnittet.
Følgende algoritme kaldes SelectionSort:
Lad U være den usorterede stak af kort, og lad S være en stak af kort, som til at starte med er tom. Gentag følgende til U er tom:Find det mindste kort i U, og sæt det bagerst i S.
Øv først lidt for at blive sikker i algoritmen. Lad to eller tre personer køre algoritmen, tag tid undervejs, og udregn gennemsnittet af tiderne.
Spørgsmål:
Angiv gennemsnittet.
| I øvelserne 3-5 og 7 får man kendskab til fire klassiske sorterings-algoritmer, hvoraf de tre første kun anvender sammenligninger på elementerne for at sortere elementerne. SelectionSort er den simpleste (men også langsomste) af disse algoritmer. |
Følgende algoritme kaldes InsertionSort:
Lad U være den usorterede stak af kort, og lad S være en stak af kort, som til at starte med er tom. Gentag følgende til U er tom:Tag øverste kort i U og indsæt det på rette plads i S, d.v.s. på en position så alle kort før det er mindre, og alle efter det er større.
Øv først lidt for at blive sikker i algoritmen. Lad derefter to eller tre personer køre algoritmen, tag tid undervejs, og udregn gennemsnittet af tiderne.
Spørgsmål:
Angiv gennemsnittet.
Beskriv metoden i bruger til at finde den "rette plads i S" detaljeret nok til at andre kan udføre den (5-10 liniers svar).
| InsertionSort er i praksis en af de absolut hurtigste sorterings-algoritmer når man sorterer få elementer. Den bliver ofte anvendt internt i mere komplekse sorterings-algoritmer. InsertionSort er et eksempel på en såkaldt inkrementiel algoritme, der hele tiden udvider en løsning for en delmængde af det oprindelige probleme ved at tilføje et nyt element. Dette paradigme kan anvendes for mange andre problemer end for sortering. En anden egenskab ved InsertionSort er at den er adaptiv med hensyn til hvor sorteret input er - jo mere input er sorteret, desto hurtigere kører algoritmen. |
Følgende algoritme kaldes MergeSort:
Lad U være den usorterede stak af kort. Lav U om til mange sorterede stakke af størrelse 2 ved gentagne gange at tage to kort fra U, lægge det mindste øverst, og lægge de to kort til side i en bunke for sig.To bunker kan nu flettes til een ny bunke ved at kigge på det øverste kort i de to bunker og flytte det mindste af de to over som det bagerste i den nye bunke (og det gentages til de to bunker er tomme).
En runde i algoritmen består i at flette de nuværende bunker sammen to og to, til bunker af dobbelt størrelse.
De nye bunker bruges i næste runde. Algoritmen består i at lave sådanne runder, til man står med kun een bunke i alt.
Øv først lidt for at blive sikker i algoritmen. Lad to eller tre personer køre algoritmen, tag tid undervejs, og udregn gennemsnittet af tiderne.
Spørgsmål:
Angiv gennemsnittet.
| Når input bliver stort så bliver SelectionSort og InsertionSort meget langsomme. MergeSort er væsentligt hurtigere end disse to algoritmer så snart input når moderate størrelser - i øvelse 8 søges en forklaring herpå. MergeSort er et eksempel på en såkaldt del-og-kombiner algoritme, der løser et problem ved at dele et problem op i mindre delproblemer og hele tiden kombinere løsninger til to delproblemer til en løsning for et problem der er dobbelt så stort. I praksis vil man ikke anvende MergeSort på bunker med to elementer fra starten. Istedet vil man starte med at lave bunker af størrelse 10-100 elementer, som hver sorteres med InsertionSort, hvorefter man anvender MergeSort. |
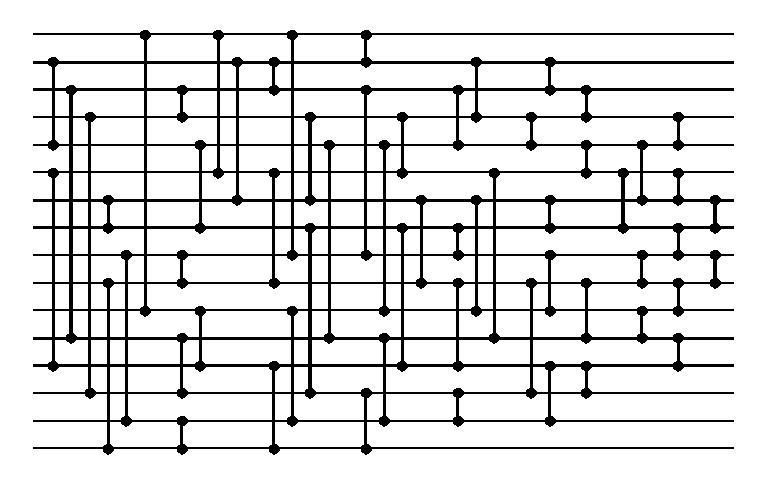
For at et sorterningsnetværk faktisk sorter input kræves det at ligegyldt hvilken rækkefølge elementerne kommer ind til venstre, så kommer disse ud i sorteret rækkefølge til højre,
Nedenstående er et sorteringsnetværk for 16 elementer der bruger 60 sammenligninger.
Læs introduktion til sorteringsnetværk som også beskriver en applet til brug for opgaven.
Følgende er links til en Java applet der tillader at man designer sorteringsnetværk for hhv:
Appleten kan checke om et tegnet netværk faktisk sorterer alle mulige input.Spørgsmål:
Hvad er de mindste sorteringsnetværk I kan finde for at sortere henholdsvis 4, 8, og 10 elementer? (Husk at uploade jeres netværk fra Java appleten)
| Sorteringsnetværk er en af de
klassiske beregningsmodeller, som er specielt defineret til
at studere sorteringsproblemet. Motivationen bag modellen er at den
ligger tæt op af hvad der er muligt med VLSI hardware, og den
tillader at man studerer hvor meget man kan parallellisere
sortingersalgoritmer (en mængde af sammenligninger der involverer
forskellige elementer kan naturligt udføres samtidigt), hvilket
studeres ved at kigge på dybden af de studerede netværk.
Det store resultat omkring sorteringsnetværk blev vist af Ajtai, Komlós og Szemerédi i 1983, hvor de viste at man kan konstruere sorteringsnetværk, således at for alle input størrelser n, så findes der et sorteringsnetværk med størrelse ≤ c1 n log n og dybde ≤ c2 log n (hvor c1 og c2 er nogle temmeligt store konstanter). Pånær konstanterne c1 og c2, så vides det at være det bedst mulige man kan opnå for både størrelse og dybde. I tidligere arbejde fra 1960'ern fokuserede man på at finde de mindste mulige størrelse netværk for små værdier af n. Algoritmerne InsertionSort og MergeSort kan ikke formuleres som sorteringsnetværk, da man for sorteringsnetværk allerede fra starten præcist skal vide hvilke (og hvor mange) sammenligninger der skal laves. Derimod giver SelectionSort direkte anledning til et sorteringsnetværk. |
Følgende algoritme kaldes RadixSort:
Algoritmen kører i runder, én runde for hvert ciffer som er i de tal, der skal sorteres.I første runde fordeles kortene fra den usorterede stak U i ti bunker efter hvilket ciffer der står sidst i tallet (på "ener-pladsen").
De ti bunker lægges oven i hinanden til een bunke, således at 9'er-bunken ligger under 8'er-bunken, som ligger under 7'er-bunken, og så videre. Man slutter med 0'er-bunken, som skal ligge øverst.
I anden runde fordeles kortene fra denne ene bunke igen i ti bunker, men denne gang efter hvilket ciffer der står næstsidst i tallet (på "tier-pladsen"). Man skal fordele kortene i bunken nedefra og opefter (d.v.s. nederste kort lægges først ud).
I tredie runde fordeles kortene fra denne ene bunke igen i ti bunker, men denne gang efter hvilket ciffer der står trediesidst i tallet (på "hundrede-pladsen"). Man skal igen fordele kortene i bunken nedefra og opefter (d.v.s. nederste kort lægges først ud).
Hvis der var flere cifre i tallene, skulle man blot forsætte med flere runder.
Øv først lidt for at blive sikker i algoritmen. Lad to eller tre personer køre algoritmen, tag tid undervejs, og udregn gennemsnittet af tiderne.
Spørgsmål:
Angiv gennemsnittet.
| RadixSort adskiller sig fra sortingsalgoritmerne i øvelserne
3-5 ved at udnytte at elementerne der skal sorteres er heltal -
hvilket muliggør at man kan opnå hurtigere algoritmer end det der er
muligt når man kun kan lave sammenligninger. I diskussionen efter øvelse
9 fremgår det at man skal bruge af størrelsesorden nlog
n sammenligninger for at kunne sortere vha. kun af
sammenligninger.
Et af de store uløste problemer i algoritmik er om det er muligt at
sortere en mængde af n heltal i tid af størrelsesorden
n.
Den hidtil bedste tid for at sortere heltal blev vist af
Han og Thorup
i 2002, hvor de præsenterede en algoritme hvor udførselstiden er
af størrelsesorden
|
Vi vil i denne øvelse prøve at vurdere, hvor lang tid algoritmerne generelt bruger på at sortere.
Det er klart at det tager længere tid at sortere, jo flere kort, der er. Hvis N står for antallet af kort, bør vores vurdering altså afhænge af N.
Men for samme N kan man godt tænke sig at den tid en algoritme bruger, afhænger af hvilken orden kortene starter i. F.eks. vil en algoritme, som starter med at kontrollere om kortene er sorteret, være hurtig hvis dette rent faktisk er tilfældet.
Vi kan derfor forsøge at sige noget om, hvad den bedst mulige og værst mulige tid er, som funktion af N.
Lad os for nemheds skyld sige at det alt i alt tager ét sekund at kigge på et kort, sammenligne det med at andet kort og evt. flytte kortet et andet sted hen.
Under denne antaglse, angiv matematiske udtryk (indeholdende N) som I mener angiver det mindste og største antal sekunder, algoritmen bruger.
Angiv også to rækkefølger af tallene 1,2,3,4,5 (d.v.s. N = 5) som giver mindste og største køretid for sortering af disse tal. Hvis mindste og største køretid er det samme (d.v.s. alle rækkefølger tager lige lang tid), skrives dette i stedet for rækkefølgerne.
Spørgsmål:
Udfyld nedenstående to tabeller:
| Algoritme | Bedste tid | Værste tid |
|---|---|---|
| SelectionSort | ||
| InsertionSort | ||
| MergeSort | ||
| RadixSort |
| Algoritme | Bedste rækkefølge | Værste rækkefølge |
|---|---|---|
| SelectionSort | ||
| InsertionSort | ||
| MergeSort | ||
| RadixSort |
| Centralt indenfor algoritmik er studiet af algoritmers udførselstid som funktion af problemstørrelsen n. Specielt er man interesseret i algoritmers asymptotiske udførselstid, dvs. hvordan udvikler udførselstiden sig når n går mod uendelige. Den asymptotiske opførsel af funktioner diskuteres videre i øvelserne 18-19. |
I denne øvelse betragter vi algoritmer som sorterer elementer ved kun at sammenligne elementer (som f.eks. InsertionSort, SelectionSort og MergeSort, men ikke RadixSort da denne kigger på de enkelte cifre i tallene). Disse algoritmer kan også beskrives ved beslutningstræer.
I et beslutningstræ antages at den eneste mulighed for at få information om input er at sammenligne to input elementer. Hvilken sammenligning man vil lave afhænger kun af svaret på de hidtige sammenligninger. Når algoritmen er færdig så ved algorimen hvordan input skal permuteres (byttes om) således at elementerne bliver sorteret - hvilket er det samme som at sige at algoritmen kender hvilken permutation input har (f.eks. hvis input er en permutation af ABC, så er der de 3! = 6 forskellige input ABC, ACB, BAC, BCA, CAB, CBA som algoritmen skal genkende). Et beslutningstræ er formelt et binært træ hvor hver knude sammenligner to input elementer, de to børn svarer til om sammenligning er sand eller falsk, og hvor hvert blad svarer til at algoritmen stopper efter at have udført sammenligningerne fra roden ned til bladet. Ved hvert blad angives de input permutationer der vil føre ned til bladet. For at et beslutningstræ svarer til en korrekt sorteringsalgoritme må der højest være en input permutation per blad: Hvis to permutationer fører ned til samme blad kan algoritmen ikke skelne disse to fra hinanden, og vil svare forkert på mindst en af disse input permutationer. Nedenstående er et beslutningstræ for et input med 3 elementer - som dog ikke svarer til en korrekt sorteringsalgoritme da der er er mere end en permutation der fører ned til det højre blad.
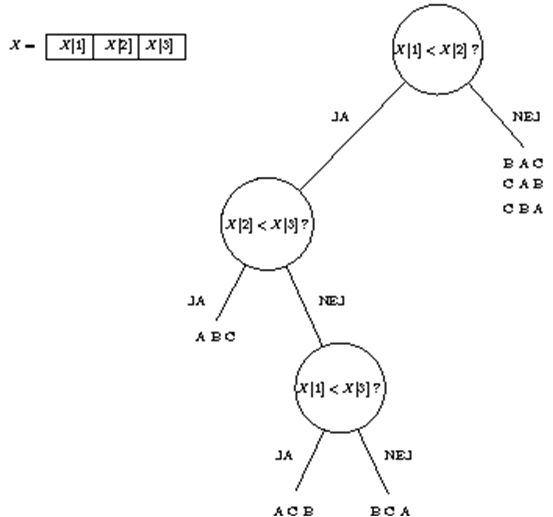
Læs introduktion til beslutningstræer som også beskriver en applet til brug for opgaven. Følgende er links til en Java applet der tillader, at man designer beslutningstræer for hhv.:
Spørgsmål:
Lav beslutningstræer for at sortere 3 og 4 elementer. Angiv dybden af jeres beslutningstræer.
| Beslutningstræer som model for sorteringsalgoritmer har sin
berettigelse, da disse indfanger alle de algoritmer man kunne komme i
tanke om, som kun laver sammenligninger på input elementerne. Man
vil (næsten) aldrig designe et beslutningstræ som sin
algoritme. Istedet bruges de til at argumentere for, at alle
algoritmer der sorterer en mængde af n elementer kun ved
sammenligninger, så vil disse tage mindst n log2 n
- 1.4427n sammenligninger på eller andet input med n elementer.
For at argumentere om at der findes en nedre grænse på dybden af et beslutningstræ for sortering anvendes følgende argumentation. Antal permutationer af n elementer er n! (= antal blade i et optimalt beslutningstræ for n elementer):
Antal blade i et træ med dybde d er højest 2d:
Ud fra ovenstående fåes følgende nedre grænser for antal sammenligninger (dybde d at et beslutningstræ) for at sortere n elementer:
F.eks. hvis n = 7, så er der 5.040 mulige permutationer, og for at et beslutningstræ skal have mindst 5.040 blade kræves at dybden er mindst 13. Generelt har vi at ⌈log2 (n!)⌉ ≥ n log2 n - 1.4427n er en nedre grænse for dybden af et beslutningstræ til sortering af n elementer. |
I denne opgave er m�let at anvende samarbejde mellem flere personer til at bringe tidsforbruget i sorteringsalgoritmer ned.
Målet er at f.eks. fire personer kan blive færdige med arbejdet på ca. en fjerdedel af tiden for een person.
Overvej for algoritmerne Mergesort og SelectionSort hvorledes fire personer kan samarbejde således at algoritmen bliver udført på ca. en fjerdedel af tiden for een person.
Spørgsmål:
Hvorledes kan fire personer samarbejde således at algoritmerne Mergesort or SelectionSort bliver udført på ca. en fjerdedel af tiden for een person?
| Når man beskæftiger sig med parallelle algoritmer, så er sortering en af de mest essentielle hjælpemetoder, hvorfor dette problem er meget velstuderet og der findes et utal af parallelle algoritmer for at sortere. Et af de største tekniske problemer ved at designe parallelle algoritmer er fastlæggelsen af hvilken model, man ønsker at beskrive sin algoritme i. Sorteringsnetværkene i øvelse 6 er en mulig model - men meget restriktiv model. De spørgsmål man skal tage stilling til er: Kan flere kigge på et element samtidigt? Kan flere skrive noget samtidigt i hukommelsen? Er man fælles om at dele hukommelsen, eller skal man også tage højde for at data skal sendes mellem hinanden?... Efter de senere års store udbredelse af kraftige grafikkort (GPU) på de fleste computere, er en stor trend for tiden at designe parallelle algoritmer, der udnytter den parallelle regnekraft der er tilstede i grafikkortenes GPUer til at løse diverse problemer. N�sten alle moderne computere (for den sags skyld ogs� mobiltelefoner m.m.) har nu til dags ogs� en central regneenhed (Central Processing Unit, CPU) der kan afvikle flere programmer samtidigt, eller tillader et program af udf�re flere mere eller mindre uafh�nginge delberegning samtidigt. |
Betragt følgende liste af tal.
30 83 73 80 59 63 41 78 68 82 53 31 22 74 6 36 99 57 43 60
Øvelsen er at slette så få af disse tal som muligt, så de resterende tal står i voksende orden. Hvis for eksempel alt på nær de første to tal slettes, har man en voksende følge tilbage af længde 2. Ved at slette alt på nær det første, tredie, ottende og tiende opnår man det samme, men har slettet færre tal og har en voksende følge tilbage af længde 4.
Spørgsmål:
Hvor lang er den længste voksende følge man kan opnå ?
| Dette er et typisk eksempel på et problem hvor man kan løse problemet ved at anvende den algoritmiske teknik der hedder dynamisk-programmering, hvor man finder løsninger til problemer ud fra kendte løsninger til mindre problemer. |
I denne opgave betragter vi to strenge hver bestående af en sekvens af bogstaverne A, C, G og T. I denne øvelse søges den længste delsekvens der forekommer i begge strenge. F.eks. angiver *-makeringerne at sekvensen AGCGATGA er en delsekvens i begge strenge, men det er nemt at se at der findes længere fælles delsekvenser.
ACTAGGTAACTTGAGTTTAGGCACGTTAGCTA
* * * * * * * *
GATTCAGGTAGTACGATCAGTAGCTAGTCTGA
* * *** ***
Spørgsmål:
Angiv en længst mulig delsekvens som forekommer i begge strenge i ovenstående eksempel.
| Endnu et eksempel på et problem man ville løser ved dynamisk-programmering. Dette problem har f.eks. anvendelser i BioInformatik hvor man ønsker at sammenligne DNA sekvenser for at finde forskelle mellem DNA sekvenser. |
Følgende er links til en Java applet der tillader at man designer hash-funktioner for tre forskellige mængder:
Spørgsmål:
Angiv for de tre input mængder en hash-funktion der spreder bedst muligt ud, dvs. en hash-funktion hvor tabel indgangen med de fleste elementer har færrest mulige elementer. (Husk at uploade jeres hash-funktion fra Java appleten)
| I
denne opgave stiftes kort bekendtskab med begrevet
hash-funktioner. Hash funktioner optræder ofte i designet
af algoritmer og datastrukturer. Nogle gange for at øge
tilgangshastigheden til data i databaser, andre gange for at
reducere den mængde data man gemmer, og et tredie eksempel er
anvedelsen i kryptografiske protokoller.
En af de mest klassiske anvendelser af hash-funktioner blev givet af Fredman, Komlós og Szemerédi i 1984, som viste at man kan gemme en vilkårlig stor mængde elementer således at man kan finde et vilkårligt element i mængden ved kun at lave to opslag vha. to hash-funktioner. |
Sammen med arrayet ønsker vi at gemme en begrænset antal forudberegnede delsummer, således at det værste antal sammenligninger for et delsum(i,j) spørgsmål altid kan beregnes ved væsentligt færre sammenligninger. F.eks. ved at gemme delsummen af den midterste 1/3 af elementerne (d.v.s summen I[N/3]+....+I[2N/3-1]), kan man besvare alle delsum(i,j) med højest 2N/3 additioner. Intuitivt så falder det værste antal additioner for delsum(i,j) spørgsmål med antallet af forud beregnede delsummer der er gemt.
Det antages at der kun må anvendes additioner på elementer (d.v.s. det er f.eks. ikke er tilladte at anvende minus).
Læs introduktion til delsum problemet som også beskriver en applet til brug for opgaven.
Spørgsmål:
Hvad er det mindste antal delsummer I behøver at gemme for et array af længde 16, således at alle delsum(i,j) spørgsmål kan besvares med henholdvis 1 og 2 additioner?
Brug appleten til at designe jeres mængde af delsummer og til at checke om alle delsum(i,j) spørgsmål kræver højest 1 og 2 additioner. Upload jeres resultat til high score listen.
| Dette er et eksempel på et datastruktur problem,
hvor man studerer forholdet mellem hvor meget plads datastrukturen
bruger og så den tid det tager på at svare på et spørgsmål til
datastrukturen. Ekstremerne er: 1) hvis man ikke gemmer noget i
datastrukturen, så må man løse problemet helt forfra når man får et
spørgsmål; 2) hvis man forudberegner svarene til alle mulige svar,
så kan man svare på et spørgsmål uden at lave nogle beregninger. Der
findes ofte en matematisk formel som indfanger denne sammenhæng.
Forholdet mellem plads og tid for ovenstående problem er blevet studeret af Alon og Schieber i 1987. |
Nedenstående viser en graf med knuder A,B,C,...,W og hvor nogle knuder er forbundet med kanter.
En sti er en sekvens af knuder hvor der er kanter imellem efterfølgende par af knuder i sekvensen, f.eks. er S,A,L,N en sti i nedenstående graf da der findes kanter mellem følgende par af knuder: (S,A), (A,L) og (L,N).
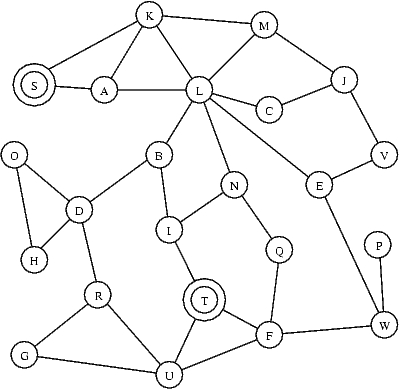
Spørgsmål:
Angiv en sti fra S til T i ovenstående graf som besøger flest mulige knuder, men hvor hver knude besøges højst een gang på stien.
| Ovenstående er et eksempel på et graf problem. Graf problemer optræder rigtigt mange steder som de essentielle problemer, når man forsøger at løse et problem: Kernen i et problem kan ofte udtrykkes som et spørgsmål om en egenskab ved en konkret graf. Ovenstående er et eksempel på traveling salesman problemet, hvor en person ønsker at besøge en mængde byer præcis én gang. Ofte vil der være afstande på kanterne, således at man skal finde den kortest vej der besøger alle byerne præcis én gang. |
I denne øvelse betragter vi grafer med vægte på kanterne.
Længden af en sti er summen af vægtene af kanterne langs stien. F.eks. har stien S,A,D,R,T vægt 27 = 4+10+5+8.
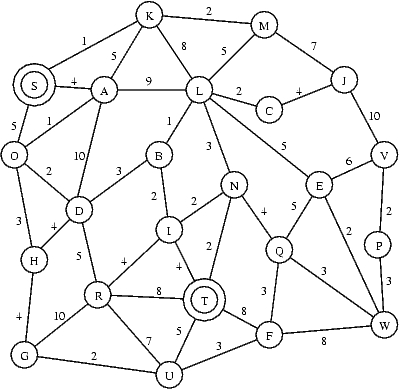
Spørgsmål:
Angiv længden af den kortest vej fra S til T i ovenstående graf.
| Dette er et andet eksempel på et graf problem, hvor man ønsker at finde den korteste vej mellem to knuder. Der findes essentielt to forskellige variationer af dette problem: 1) Givet en graf og to knuder, find den korteste vej mellem de to knuder; 2) Givet en graf med vægte på kanterne, forudberegn en datastruktur for grafen, således at man hurtigt kan svare på spørgsmål om den korteste vej mellem to knuder uden at kigge på hele grafen. Dette er f.eks. kerneproblemet der løses i Google Maps, Krak etc. |
I denne øvelse skal der vælges en person fra gruppen til at hente et ark med puslespil (puzzle.pdf) fra instruktoren. Arket indeholder tre puslespil, som alle handler om at samle polygoner til et kvadrat. Der er tre puslespil, med 2, 4 og 8 brikker.
Uden at vise de andre arket (da løsningen i så fald bliver kendt), klipper personen brikkerne ud.
Tre andre personer løser derefter hvert sit puslespil (vend brikkerne om, så eventuelle rester af streger ikke kan bruges som hjælp).
Tag tid på løsningen (stop løsningen af det store puslespil efter 5 minutter, hvis man ikke har løst det inden da).
Spørgsmål:
Angiv tiden for de tre løsninger.
2 brikker:
4 brikker:
8 brikker:
| Denne opgave illustrerer et meget simpelt eksempel på et kombinatorisk problem, hvor sværhedsgraden af problemet vokser voldsomt hver gang problemstørrelsen fordobles. For mange puslespils lignende problemer findes der for input af størrelse n potentielt eksponentielt mange måder at komme frem til en løsning (f.eks. 2n muligheder eller det der er værre). For mange af disse problemer findes der kun algoritmer til at løsse disse ved essentielt at prøve alle mulige løsninger af én-for-én. |
To simple matematikopgaver.
De må gerne besvares ved afprøvning på lommeregner eller ved plot af funktioner på grafisk lommeregner.
Spørgsmål:
Fra og med hvilket N er 0.01*N2 større 100*N ?
Fra og med hvilket N er 0.0001*2N større 10000*N ?
| I denne øvelse skal man sammenligne funktioner, der kunne svare til udførselstiden for forskelige algoritmer. Indsigten man skal opnå er at for store problem-størrelser er det ikke de foranstående konstanter der bestemmer hvilken algoritme der er hurtigst, men den asymptotiske opførsel når n går mod uendelig, f.eks. at n er hurtigere end n2. Typisk vil komplekse algoritmer have en udførselstid karakteriseret ved store konstanter med bedre asumptotiske tider end simple algoritmer, der typisk vil have udførselstid karakteriseret ved små konstanter men dårligere asymptotisk tid. |
Endnu en matematikopgave.
Vi ser her på to computere, X og Y. Den gamle computer X kan lave 1.000.000 beregninger per sekund, mens den helt nye model Y kan lave 1.000.000.000 beregninger per sekund.
For forskellige køretider for algoritmer ønsker vi nu at beregne hvor store input der kan behandles inden for en givet tidsfrist.
Udfyld nedenstående tabel med største værdi af inputstørrelsen N, der kan behandles inden for det angivne tidsrum og på den angivne computer, når køretiden for algoritmen, udtrykt ved størrelsen N af input, er som angivet.
Spørgsmål:
Udfyld følgende tabel:
| Køretid | X i et sekund | X i et år | Y i et sekund | Y i et år |
|---|---|---|---|---|
| N | ||||
| N*log(N) | ||||
| N2 | ||||
| 100*N2 | ||||
| N3 | ||||
| 2N |
| Denne øvelse ligger i forlængelse af øvelse 18, og giver konkrete eksempler på funktioner man typisk møder når man analyserer algortimer. Opgaven skal desuden give et indtryk af hvor store problemer man realistisk kan løse med algoritmer med forskellige asymptotiske udførselstider - f.eks. at man med algoritmer med eksponentielle udførselstider ikke er i stand til at løse specielt store problemer. |
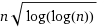 .
.